Dec 16, 2019
How to build a data pipeline with StreamSets and Aiven
It used to take months to design and build a data pipeline. Now you can do it in minutes with open source tools and Aiven managed services.

John Hammink
|RSS FeedDeveloper Advocate at Aiven
What if you could design and build a complete data architecture in minutes instead of months? And what if you could accomplish this using free and open source tools?
Previously, we’ve always thought about the data pipeline as the domain of the Data Engineer - and that skill stack necessarily includes those of the architect, software developer, database and messaging system admin, and a pile of other things.
In fact, it’s probably not an unreasonable hypothesis that in data engineering, the Pareto principle applies: 80% of the effort makes up only 20% of the output. And what is that 80%? Installs, maintenance and updates, bringing down nodes back up, running ZooKeeper, while partitioning and sharding — along with major upgrades — also play a factor.
And then there are all the homespun scripts, programs, connectors and configurations that have to be made! This would seem especially true when using open source tools, where you have to be sure that your budget gets you the one person (or dedicated team) with all the right chops.
But what could you do if you didn't have to go through with all that? What if you could leverage easy, plug-and-play architectures in your data pipelines alongside managed services? The time and money you could save will, of course, free up your resources to serve up data to your customers and organization in newer, better, and more innovative ways.
And you'll have more of those resources, because with an abstraction layer simplifying your dataflow, you don't even NEED to be a data engineer anymore to build pipelines! As mentioned, that doesn’t mean the need for data engineers’ skills will go away - it just means that those precious engineering chops can be put to better use.
In this article, we'll build a complete, end-to-end data pipeline using drag-and-drop assembly alongside hosted, managed persistence services. We’ll leverage StreamSets' open source drag-and-drop data pipeline builder, Data Collector, along with Aiven's hosted and managed Apache Cassandra and OpenSearch. And we'll go from ingesting log data to running analytics queries in our data stores (what before has taken months) in minutes!
The short version - Logs via Data Collector into OpenSearch
**NOTE: I’ve used steps particular to my setup and environment, which you may need to adjust. You’ll need a little fluency with the technologies used here, so your mileage may vary.
In this first part, we’ll read logs from our local directory (stored under the Data Collector), tweak a few things and send events containing a couple of fields, namely geo (latitude and longitude), referrer, clientip, timestamp, and city into our logs index on our Aiven for OpenSearch instance.
A real production use case might retrieve log files via FTP, or from S3, but a local directory is convenient for our purposes here.


You’ll need to set up a few things first. (We’re basing this first part largely on this log ingestion tutorial from StreamSets, so you’ll also see some — but not all — of the steps and prerequisites laid out there. In particular, that tutorial does not use the Docker image). We’ll point out <variables> where appropriate.
Download the sample data and GeoIP database, and store it somewhere convenient.
You can also download this script to generate more voluminous logs in real time.
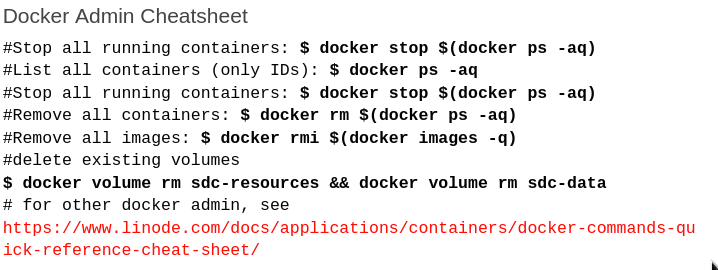
First, you’ll want to get a version of StreamSets’ open source Data Collector. For demos, I’ll often take the Docker variant. You’ll want to create a few Docker volumes for use in your Data Collector pipeline:
$ docker volume create --name sdc-resources $ docker volume create --name sdc-data #optional, but recommended
Download and run the docker version of StreamSets Data Collector, taking both volumes into use:
$ docker run -v sdc-resources:/resources -v sdc-data:/data -p 18630:18630 -d --name sdc streamsets/datacollector dc
Once it’s up, you can sanity check Data Collector in your browser.
URL: http://localhost:18630/
login: admin/admin
Next, copy your sample data under your volumes, so you can access the data from Data Collector. First, the Geolite database:
$ docker cp GeoLite2-City.mmdb sdc:/resources
Add the source log files into Data Collector resources:
$ docker cp access_log_20151221-101535.log sdc:/resources $ docker cp access_log_20151221-101548.log sdc:/resources $ docker cp access_log_20151221-101555.log sdc:/resources ...601... ...666...
You’re ready to spin up your Aiven for OpenSearch instance. You can use Aiven Console, but if you’re using Aiven CLI, then:
$ avn service create es-sstutorial -t elasticsearch --plan hobbyist
Once the service is created, and up and running, you’ll need to create an OpenSearch index, into which to pipe your processed data from your source logs.
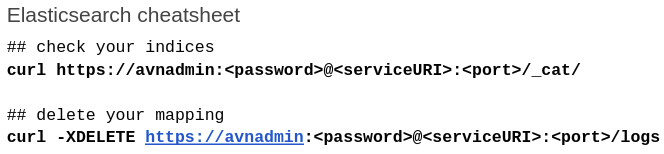
For the sake of brevity, let’s say we want to collect just our timestamp and geo fields, so we can analyze what is coming from where, when. Copy the service URI for your Aiven for OpenSearch instance. And then create the root mapping for your index:
NOTE: Newer versions of OpenSearch require the _doc mapping.
$ curl -X PUT -H "Content-Type: application/json" 'https://avnadmin:<password>@<serviceURI>:<port>/logs?include_type_name=true' -d '{ "mappings": { "_doc" : { "properties" : { "timestamp": { "type": "date" }, "geo": { "type": "geo_point" } } } } }'
Next, we’ll create the pipeline that processes our logs and stashes the results into our OpenSearch instance.
For this first part, I’ll be sticking to a basic description, but you can find a more detailed one complete with Data Collector screenshots and explanations — upon which this first part was based — at the link.
Open the Data Collector and create a new pipeline.
Drag the Directory origin stage onto your canvas.
Under Configuration => Files point your Files Directory to /resources as shown. I unzipped the logs and so used the *.log as a File Name Pattern, with the ...Mode set to Glob.
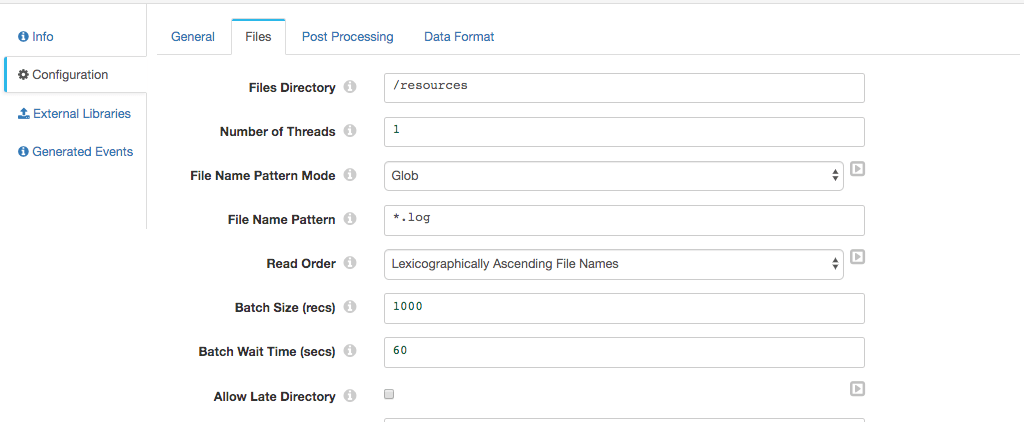
Set Post Processing => File Post Processing to None. Under Data Format set:
- Data Format:
Log - Log Format:
Combined Log Format
Now, lets define our geo field. Drag and drop an Expression Evaluator onto your canvas. Go to Configuration => Expressions and set Output Field to /geo and the Field Expression to ``$${emptyMap()}. This creates a Map``` data structure that we’ll populate with the value of our geo object.
Now, we’ll need to convert a few of our fields from their default text types to numeric values, in particular Response Code, Bytes and the DATETIME timestamp. Drag and drop a Field Type Converter into the pipeline. Now, go to Configuration => Conversions and fill it in accordingly:
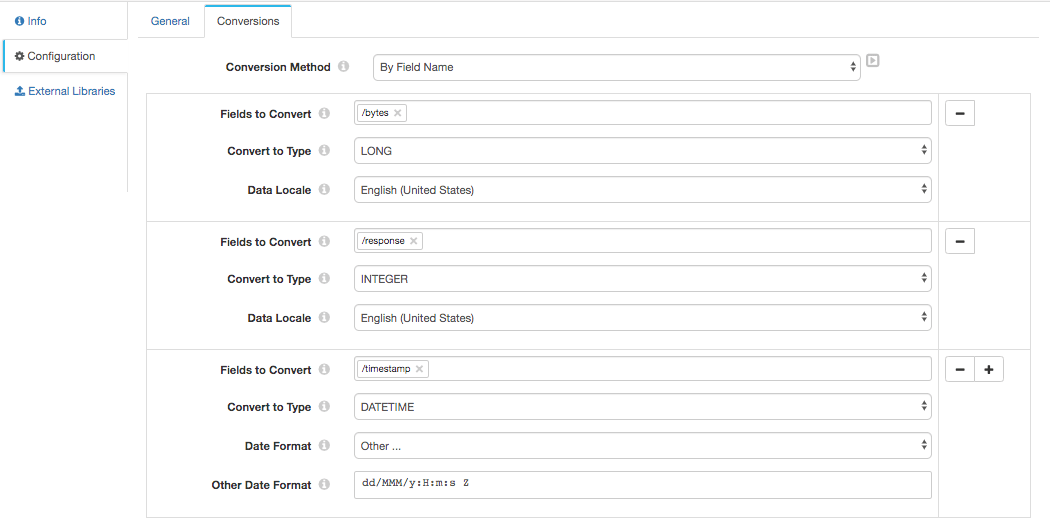
NOTE: This will require a few extra steps, including converting the Date Format. That format string is dd/MMM/y:H:m:s Z. Remember to use the + button to add conversions.
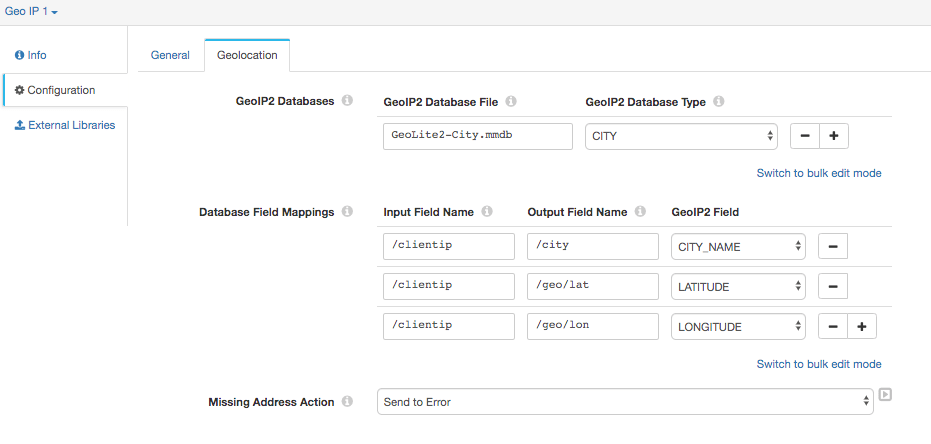
In our next stage, we’ll need to perform a GeoIP lookup, and process three related fields. Drag and drop a GeoIP stage into your pipeline. In it, go to Configuration=>Geolocation and fill in the settings accordingly:
Finally, we’re going to add our Aiven for OpenSearch as a destination. Drag and drop an OpenSearch stage onto the canvas, filling Configuration=>OpenSearch settings as follows:
- Cluster HTTP URIs:
https://<serviceURI>:<port> - Time Basis: ``$${time
()}``` - Index:
logs - Mapping:
_doc
Configuration=>General
- Name:
Aiven for OpenSearch
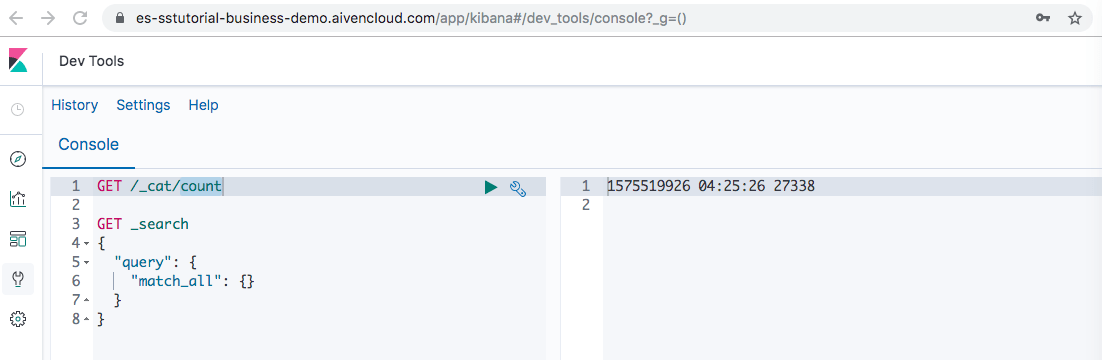
While testing everything out, you can use the Data Collector’s Preview Mode to run the pipeline and OpenSearch dashboards Dev tools Console instance associated with your Aiven for OpenSearch instance to count records and query your indexes to verify the data is delivered:
The longer version - dual ingest: OpenSearch and Cassandra
A more realistic scenario involves a dual ingest — a lambda architecture — where some data goes to one store with one purpose and some of our data goes to another. While we’re already ingesting some of our data into OpenSearch, we’d like to ingest a few of the fields into Cassandra for long-term storage and analytics in CQL.
An actual lambda architecture would also typically involve performing real-time processing on the stream.
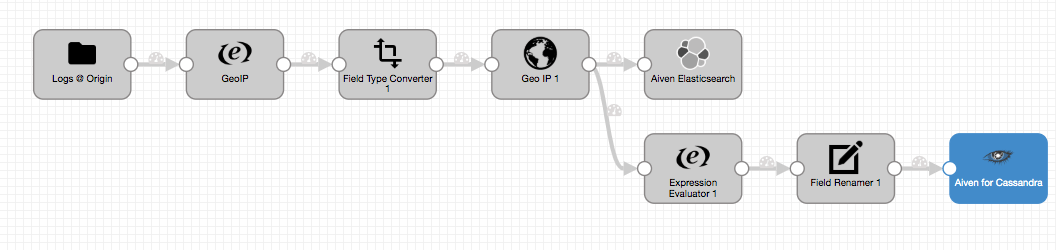
For our purposes, we’re going to import three fields into Aiven for Apache Cassandra: uuid, city_name, and referrer. Cassandra needs a unique row identifier, so we’ll modify the pipeline to create a uuid field, and use the city_name, and referrer fields from the log data.
You’ll need to spin up an Aiven for Apache Cassandra instance, again, using either Aiven Console, or Aiven CLI, as in:
$ avn service create cassandra-sstutorial -t cassandra --plan startup-4
Once your Cassandra service is up, download ca.pem from your Aiven for Apache Cassandra service to the folder you wish to run CQLSH from.
ca.pemis accessible on Aiven Console from your Aiven for Apache Cassandra service under the service’s Overview => Connection information.
Here’s the connection string you’ll need to connect CQLSH to your Aiven for Apache Cassandra instance:
SSL_CERTFILE=ca.pem cqlsh --ssl -u avnadmin -p <aiven_for_cassandra_password> --cqlversion="3.4.4" <service_URI> <port>
You’ll also need to add an authentication connection from Aiven for Apache Cassandra to the Data Collector. This involves generating a truststore.jks using that same ca.pem and copying it to the docker Data Collector instance:
$ keytool -import -file ca.pem -alias CA -keystore truststore.jks pw: <your_password> trust: yes $ docker cp truststore.jks sdc:/resources
From your CQLSH prompt, go ahead and create the keyspace and table you’ll be importing the data into your Aiven for Apache Cassandra instance:
CREATE KEYSPACE location WITH REPLICATION = {'class': 'NetworkTopologyStrategy', 'aiven': 3}; USE location; CREATE TABLE city (UUID text PRIMARY KEY, city_name text, referrer text);
Deleting your Cassandra table as a cleanup step is easy:
DROP TABLE city;
Let’s add a few more stages to your pipeline to connect to Cassandra.
First, get an Expression Evaluator and connect it with a new arrow to the Geo IP stage that we connected to OpenSearch. Under Configuration=>Field Expression, create the following mapping:

Lets grab a Field Renamer and connect it as our next stage, with the following mapping:
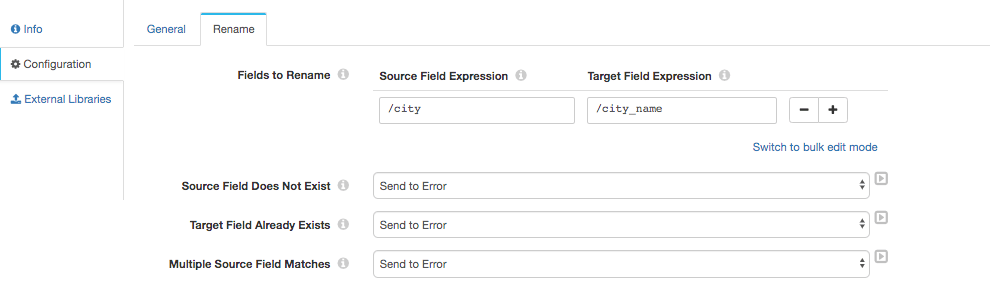
It’s possible to skip the Field Renamer stage and simply map
/citytocity_namein the Cassandra destination stage.
Finally, we’ll create our Aiven for Apache Cassandra destination in the Data Collector. Connect in a Cassandra stage, configuring it as follows:
Configuration=>General
- Name:
Aiven for Apache Cassandra
Configuration=>Cassandra
- Cassandra Contact Points:
https://<serviceURI> - Cassandra Port:
<port> - Remaining settings as below:
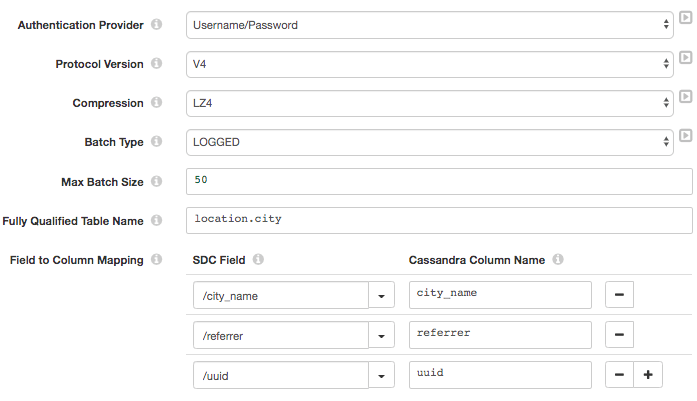
Fill Configuration=>Credentials with the Username and Password provided by your Aiven for Apache Cassandra service. Finally, under Configuration=>TLS, specify Java Keystore file (JKS)as the Keystore Type, and truststore.jks as the Truststore File.
Up and running!
Here’s what it looks like running (wait a few seconds); first counting and querying data going into our Aiven for OpenSearch instance:
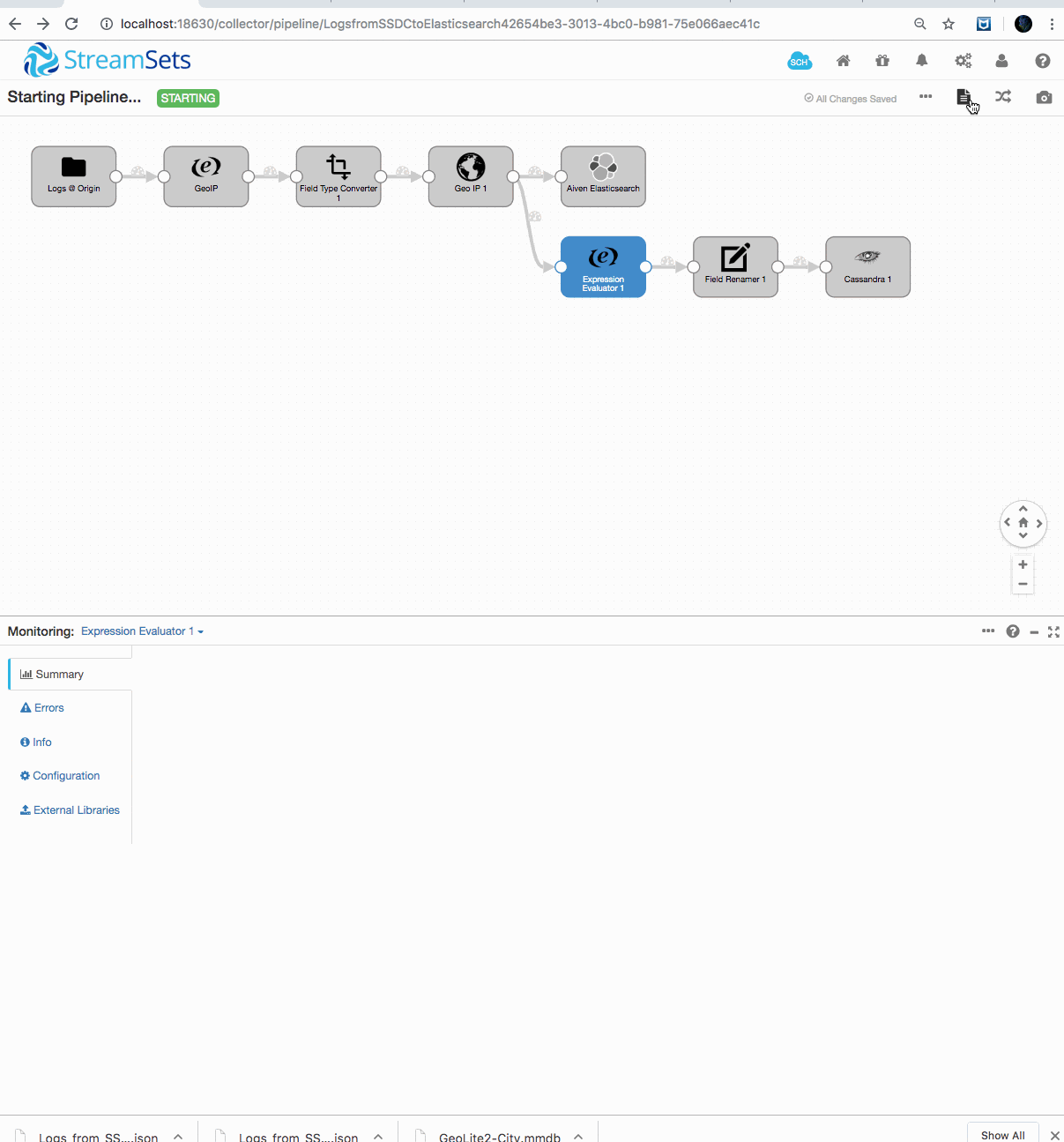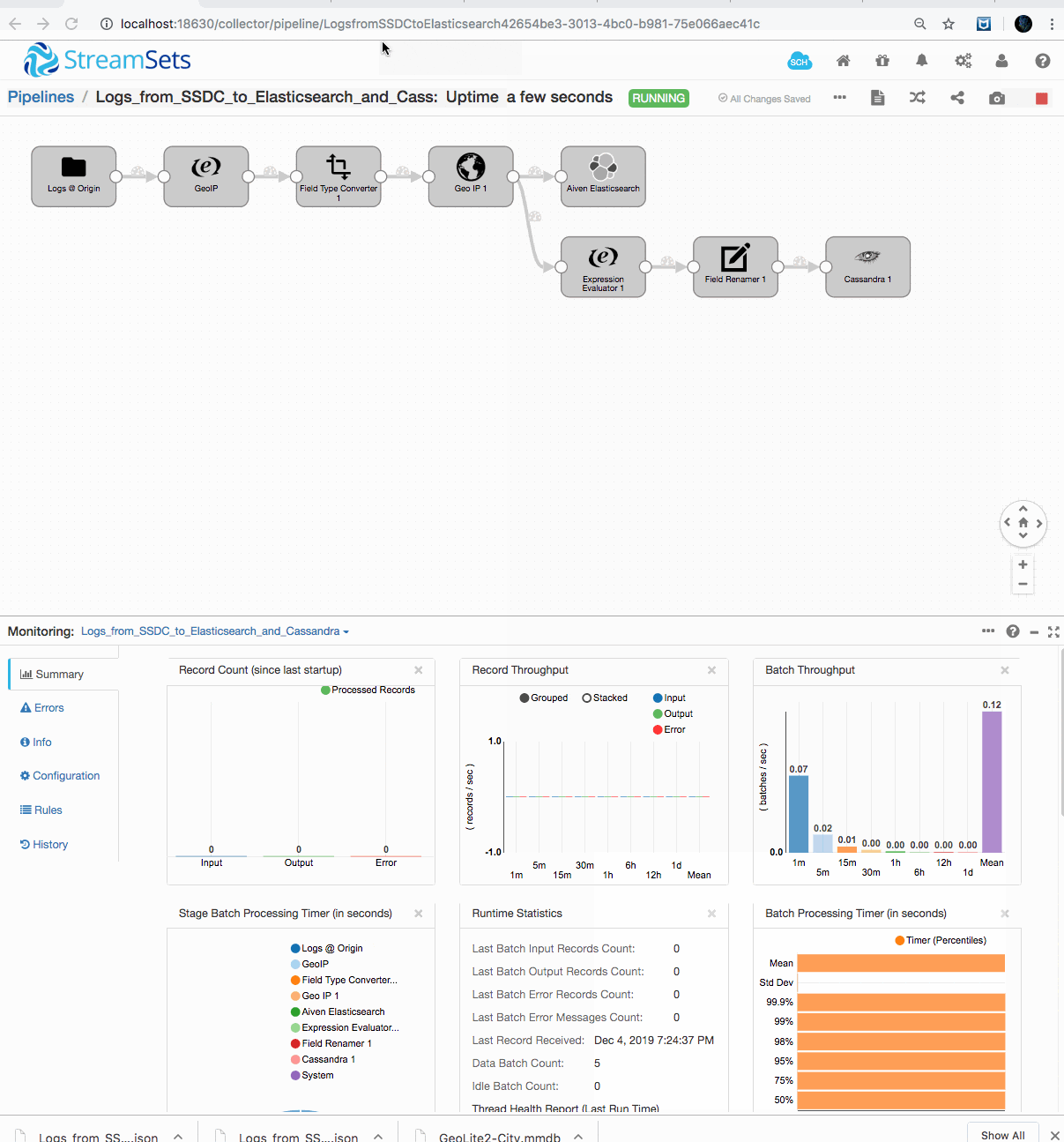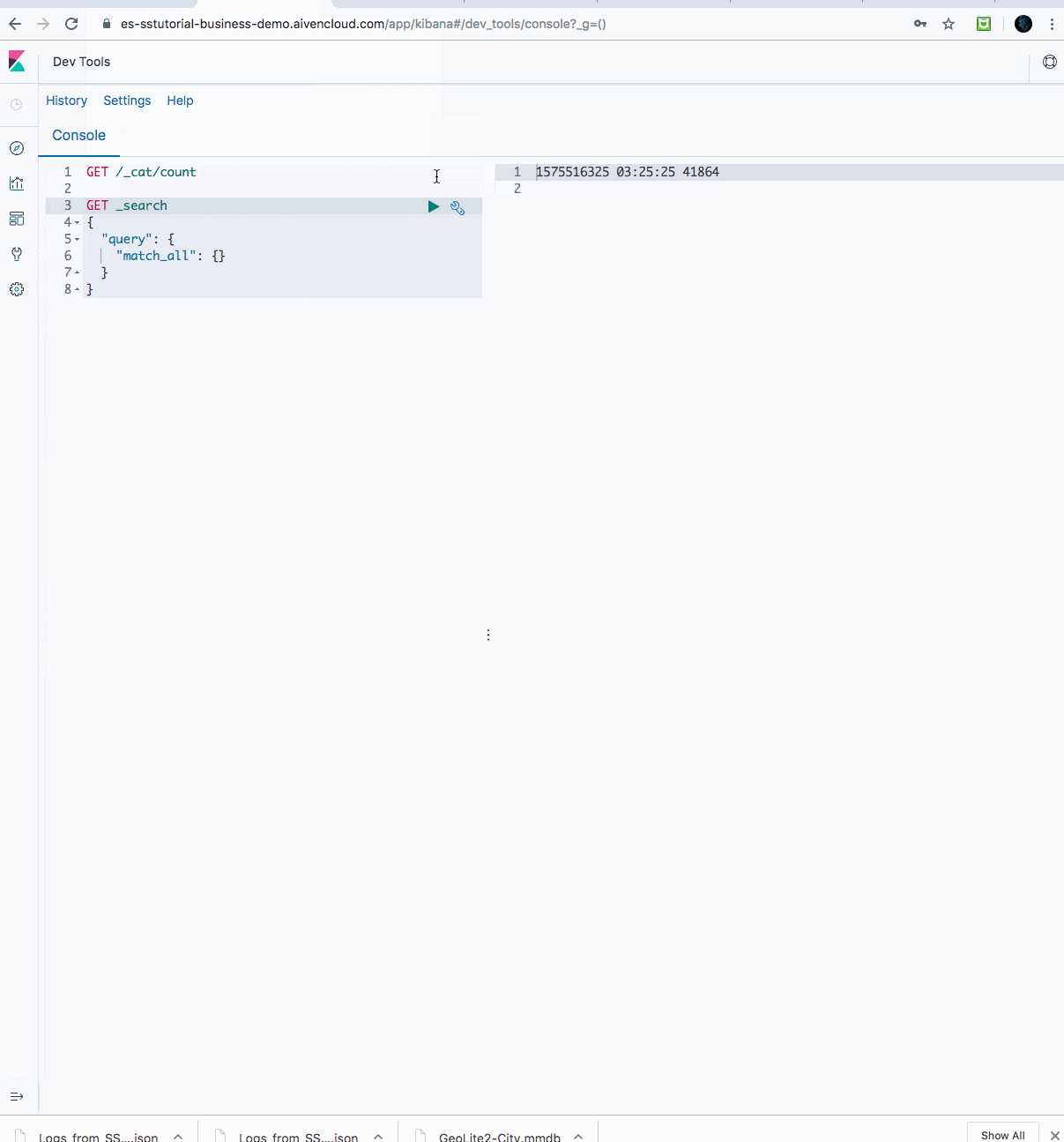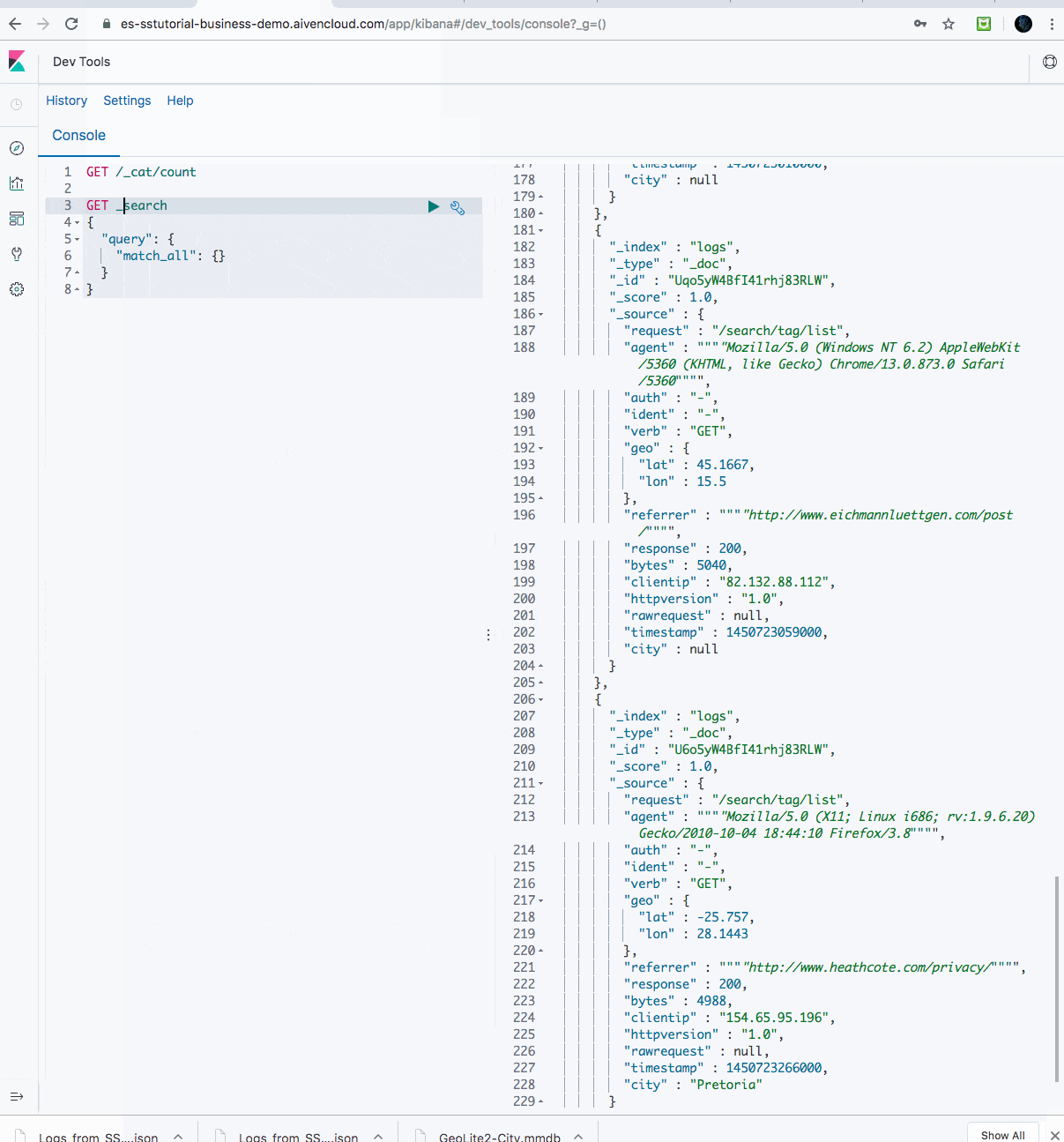
And finally, counting and querying data in as it goes into Aiven for Apache Cassandra:
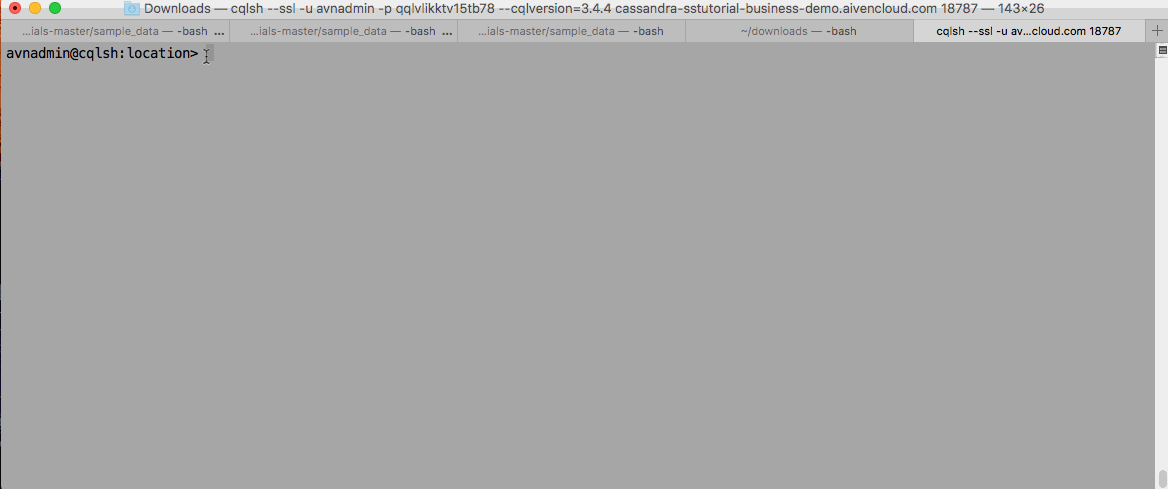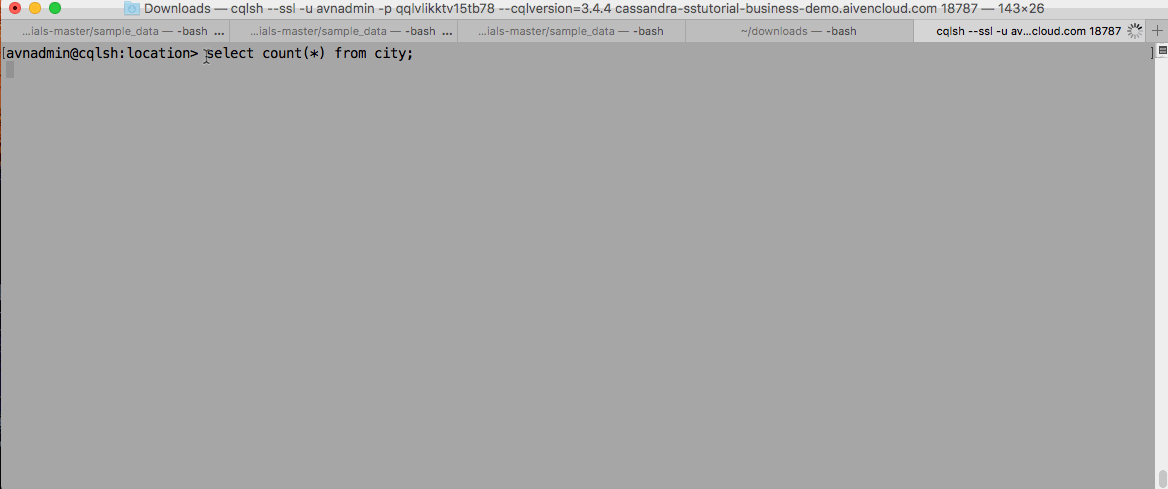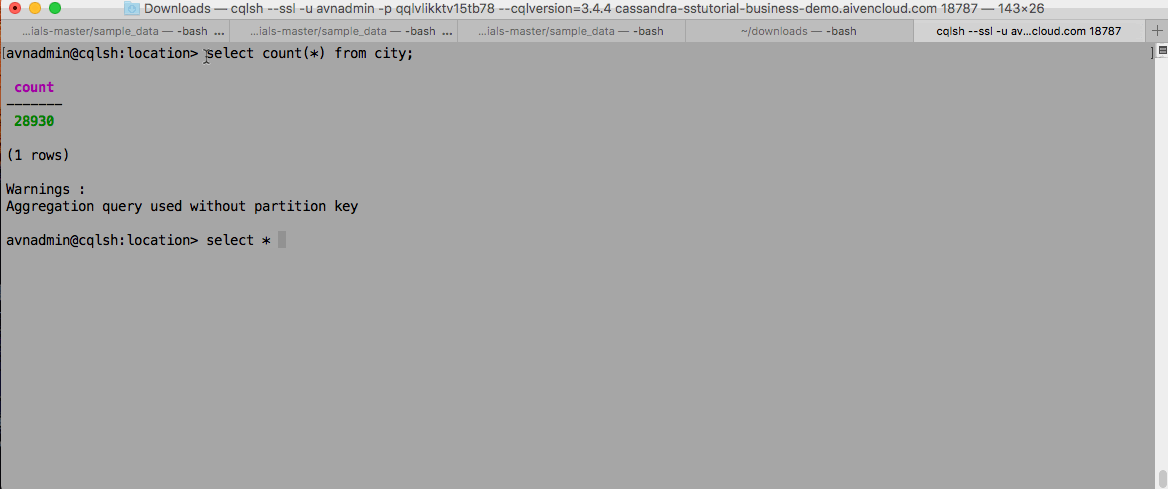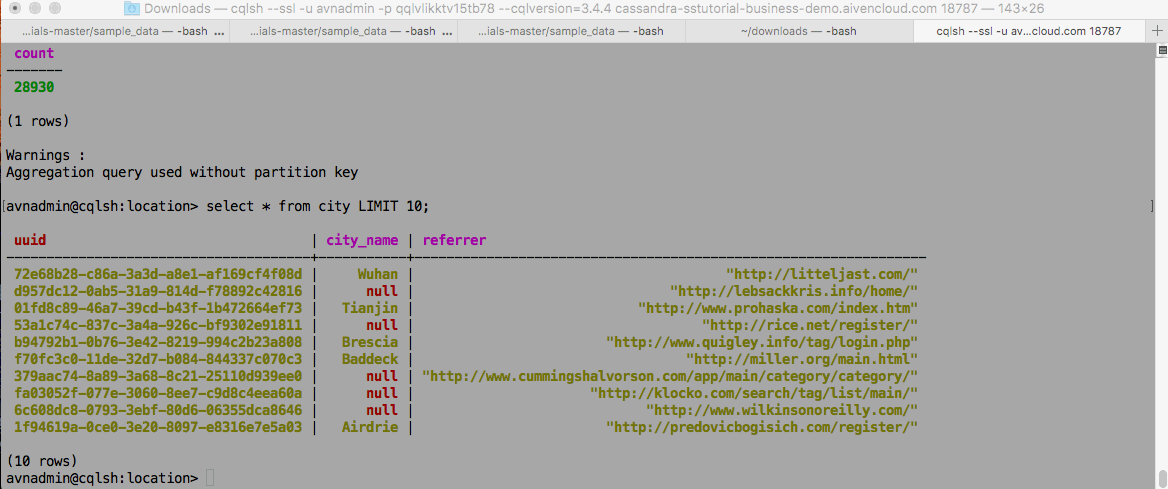
Wrapping up
We've just built a complete, end-to-end data pipeline via drag-and-drop leveraging StreamSets Data Collector along with Aiven's hosted and managed Apache Cassandra and OpenSearch.
If you got stuck, here’s a link to the pipeline
.jsonon github.
With StreamSets Data Collector and Aiven managed services, you can not only build what took months in minutes, but you don’t need to burn time on the day-to-day stuff.
We’ll be doing many more integrations like this one, so remember to follow our blog, changelog RSS feeds, or catch us on Twitter or LinkedIn to see what's happening.
Many tips of the hat go to Pat Patterson for making things work even better! Thanks Pat.
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


